
That was the situation pollsters found themselves in after the May 2015 general election in the UK. A dead heat between Labour and the Conservatives was forecast, but the Tories emerged with a small but comfortable majority.
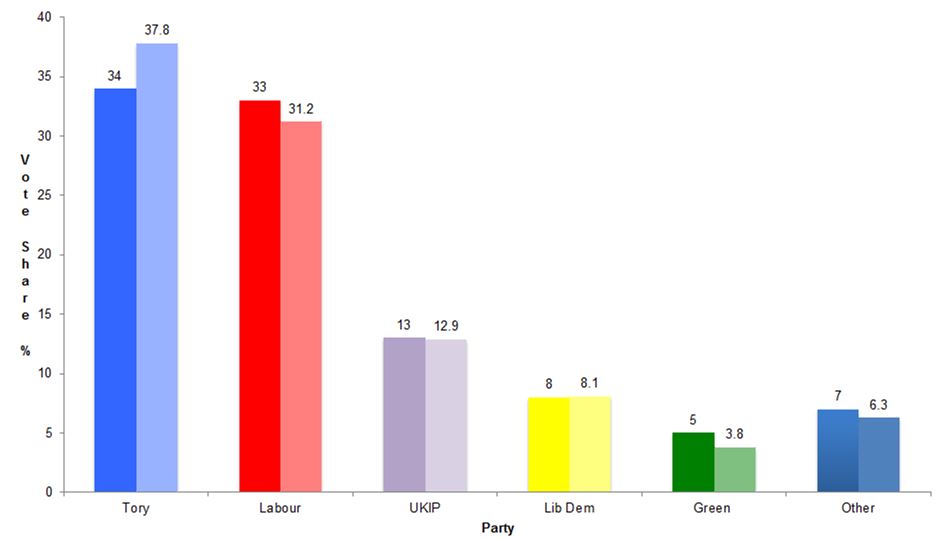
Figure 1. 2015 election result versus average of final polls (GB). Chart by Patrick Sturgis.
This was obviously seen as bad news for the pollsters. It’s no secret that the companies who carry out most pre-election surveys make very little money from the polls themselves. They do them, essentially, to demonstrate their prowess to marketing directors and brand owners – the kind of people who want to know what their customers are thinking and would like to hire a reliable company to find out. But if a company can’t accurately measure voting intention, can they be trusted to find out whether brand A, B or C is most popular?
That’s a question buyers of opinion surveys might have found themselves asking since May. It’s too soon to say definitively whether the failure of the 2015 polls has had or will have a noticeable impact on revenues, but at least one pollster appears to have emerged unscathed.
Whodunnit?
But what about survey research more broadly? What does the failure of the polls tell us about the future of survey research? This was the question tackled last week by Patrick Sturgis, professor of research methodology and director of the ESRC National Centre for Research Methods at the University of Southampton, at the annual Cathie Marsh Lecture.
Sturgis began by drawing a distinction between ‘polls’ and ‘surveys’, the former being “what pollsters do”, the latter being “what academics and official statisticians do”. That’s a somewhat crude distinction perhaps, so he narrowed it down on the basis of quality and methodology, with polls being defined as “low quality” using non-random samples, while surveys are “high quality” using random samples (and typically employing face-to-face interviewing methods, rather than telephone or web-based methods).
This methodological distinction was important to make, as methodological issues may be to blame for the failure of the 2015 election polls. Sturgis wasn’t able to talk in much detail about likely culprits at this stage, given that he is chairing an inquiry into the elections polls. However, he pointed to several key suspects, including question design, postal voting, and sampling and weighting. The latter is perhaps where polls and surveys differ most sharply. As Sturgis explained, an academic survey might draw a random sample of respondents from the general population, which – in theory – gives everyone an equal chance of being selected to participate. Polls however don’t work to the same rationale, he said. “They are essentially modelling exercises using recruited panellists.”
Voter turnout was another likely suspect, Sturgis said. As he described it, pollsters can only base their samples on the voting-age population of the UK, but the population of actual voters – the ones who go out and cast a ballot – is unknown, and so pollsters might end up surveying more of the people who don’t vote and not enough of the ones who do.
Late swings in support from one party to another might also have played a part in the failure of the polls, as might non-response, especially if those refusing to be surveyed, or those who say they don’t know how they will vote, disproportionately ‘break’ for one party over another when election day comes.
Not so unexpected
Sturgis’s argument – and his reason for making the distinction between polls and surveys – was that the failure of the polls shouldn’t be read as a failure of survey methods. Students are taught that surveys should ideally ask questions of carefully drawn samples of well-defined populations, and that those questions should ask about well-defined behaviours that have occurred during a well-defined period. In contrast, Sturgis said, polls ask a poorly-defined population (likely voters) about behaviour that may take place in the future – answers to which may be subject to social desirability bias.
Bearing this in mind, Sturgis said it was more surprising to find that polls get close to the actual result, not that they are – on occasions – wildly off the mark. Indeed, he said, these sorts of “big misses tend to happen every 20 years”, repeating a remark previously made by GfK NOP pollster Nick Moon.
In historical terms, Sturgis said, 2015 was by no means the pollsters’ worst performance, though it came close reasonably as can be seen in Figure 2, which plots the mean absolute errors on reported Conservative/Labour leads from 1945 to the present day.
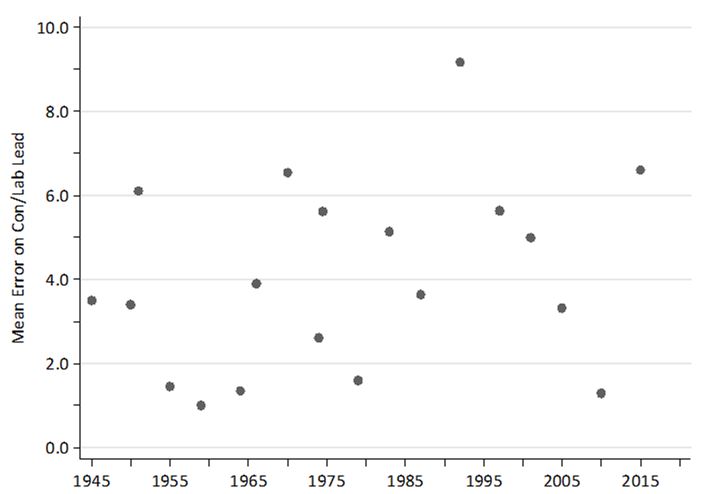
Figure 2. Mean absolute error on Con/Lab lead 1945-2015. Chart by Will Jennings.
Of course, the fact that the 2015 polls weren’t quite as bad as they have been in the past doesn’t excuse pollsters from trying to identify and correct what went wrong. For their own sakes, and for the sake of the businesses they promote, they will be desperate to avoid making the same mistakes in future.
But as for survey methods in general, Sturgis said the effect of the polling failure is likely to be minimal, especially as proponents of “high quality” random sample designs can point to the success of the 2015 exit poll in support of the argument that surveys do still work – especially when you’re asking actual voters how they actually voted, rather than asking likely voters how they’re likely to vote.


