
<script language="javascript" type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS-MML_HTMLorMML">
</script>
<script type="text/x-mathjax-config">
MathJax.Hub.Config({tex2jax: {inlineMath: [['$','$'], ['\\(','\\)']]}});
</script>
{/source}
In common with many modernist artists active in the fi rst half of the 20th century, Joyce's books encompass very di fferent styles. He went on from an extraordinarily accomplished collection of short stories (Dubliners, first published in 1914) to write three of the most famous novels of the 20th century: A Portrait of the Artist as a Young Man (1916), Ulysses (1922), and Finnegans Wake (1939), in which experimental forms of expression are increasingly used.
For example, Ulysses has many puns in different languages, as does Finnegans Wake which also includes several made-up words with more than 100 letters. These two novels have often been described as di fficult, and particularly the latter as unreadable or worse1, but are they? In particular, do they have a much wider vocabulary, and are they harder to read than other texts by Joyce?
A description of vocabulary richness is often the starting point of a statistical analysis of texts. A word token is an instance of a particular word type. For example, this is the opening sentence of Ulysses:
'Stately, plump Buck Mulligan came from the stairhead, bearing a bowl of lather on which a mirror and a razor lay crossed.'
This has 22 word length tokens and consists of 20 types of which 3 are of the type 'a'. Note that words like 'mirror' and 'mirrors' are considered diff erent tokens though they are instances of the same word, and 'Buck' and 'buck' are considered the same token whilst being di fferent words.
The vocabulary size of a text is the number of di fferent word types, whilst its length is the number of different word tokens. A well-known problem when measuring vocabulary richness is their strong dependence on the text's length measured in word tokens. Tweedie and Baayen studied many statistics of lexical variability and identified three functions of the types' distribution which are theoretically constant with respect to text length. Perhaps the best known of them is Yule's K function2.
Regarding readability, a popular measure is Flesch's reading ease score (RES)3. This is a standard measure for readability and continues to be used extensively in many areas, such as evaluating the readability of clinical protocols.
Using these methods, I looked to examine the quantitative aspects of a large part of the Joycean canon: the 15 short stories collected in Dubliners, and the three novels. These analyses are not at all concerned with the books' meaning: they refer to purely numerical features of the texts, in particular to their distributions of word frequencies and of sentence length4.
The figure below shows the results for the 18 texts. As expected, there is a weak negative correlation between reading ease and vocabulary richness (Spearman's 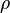 = 0.20). Clearly Ulysses and Finnegans Wake have by far the most complex vocabularies thus reflecting the extent of Joyce's experimental writing. Meanwhile A Portrait…, and The Dead, which is structurally diff erent to other stories in Dubliners, and A Little Cloud are at the richer end of the vocabulary spectrum (K < 100).
= 0.20). Clearly Ulysses and Finnegans Wake have by far the most complex vocabularies thus reflecting the extent of Joyce's experimental writing. Meanwhile A Portrait…, and The Dead, which is structurally diff erent to other stories in Dubliners, and A Little Cloud are at the richer end of the vocabulary spectrum (K < 100).

The table below shows the results in more detail. The order of the stories in Dubliners is how they are arranged in the book, and corresponds to the four aspects Joyce mentioned in a letter to his publisher: childhood, adolescence, maturity, and public life.
Finnegans Wake has the largest rate of syllables per 100 words as a result of including comparatively so many made-up words. Across all the books, there are interesting differences in the sentences with the longest lengths (as summarised by their 99% quantile: Q99). The longest 1% of sentences in Dubliners are much shorter than the equivalent sentences in the novels, with Finnegans Wake's Q99 = 152, roughly twice the values of the other two novels, and three times the average Q99 in Dubliners.
| Text | Tokens | Types | Yule's K | Readability Ease Score | Syllables per 100 words | Mean sentence length | Q99 of sentence length |
| Dubliners | |||||||
| The Sisters | 3083 | 910 | 104.3 | 79.6 | 130.7 | 16.4 | 48 |
| An Encounter | 3242 | 988 | 101.7 | 76.6 | 132.2 | 18.1 | 42 |
| Araby | 2328 | 824 | 137.6 | 79.8 | 130.2 | 16.6 | 49 |
| Eveline | 1819 | 637 | 141.2 | 81 | 131.4 | 14.4 | 41 |
| After the Race | 2230 | 865 | 131 | 68.8 | 143.5 | 16.4 | 52 |
| Two Gallants | 3902 | 1141 | 112.5 | 81.9 | 131.4 | 13.5 | 36 |
| The Boarding House | 2787 | 935 | 107.7 | 75.8 | 134.4 | 17.1 | 51 |
| A Little Cloud | 3770 | 1165 | 91.8 | 80.2 | 137.9 | 9.8 | 44 |
| Counterparts | 1877 | 640 | 130.4 | 86.7 | 133.3 | 7.3 | 47 |
| Clay | 2521 | 706 | 135.6 | 76 | 128.1 | 22.1 | 66 |
| A Painful Case | 3622 | 1233 | 121.2 | 68.8 | 142.3 | 15.8 | 47 |
| IvyDay in the Committee Room | 5204 | 1247 | 105.3 | 82.9 | 132.1 | 11.9 | 62 |
| A Mother | 4508 | 1184 | 111.8 | 70.3 | 142.4 | 15.8 | 44 |
| Grace | 7487 | 1817 | 111.2 | 74.9 | 140.9 | 12.6 | 46 |
| The Dead | 15603 | 2775 | 92.5 | 77.3 | 133.9 | 16.1 | 57 |
| Novels | |||||||
| A Portrait of the Artist as a Young Man | 84713 | 13944 | 95.9 | 76.1 | 134.8 | 16.5 | 70 |
| Ulysses | 264185 | 30148 | 77.6 | 74.8 | 141.8 | 11.9 | 76 |
| Finnegans Wake | 228626 | 57637 | 81.7 | 62.8 | 150 | 16.9 | 152 |
Surprisingly, none of these texts is classi fied by RES as being even fairly di fficult, but this is surely due more to this score being a rather blunt instrument than to the actual complexity of the texts. It is personally reassuring though that the book with the highest difficulty rating is Finnegans Wake, which, unlike Ulysses, I found impossible to read.
Still, the general answer to the title of this article must be 'not at all'. In Two More Gallants, a short story directly inspired by Dubliners written by William Trevor and first published in 1986, a character brings a practical joke to closure by declaring that 'our friend Jas Joyce would definitely have relished that'. I can only hope that this could also be said about this brief analysis.
Footnotes
- 1. The mathematician GH Hardy is reported to have said 'Young men ought to be conceited: but they oughtn't to be imbecile' after someone had tried to persuade him that Finnegans Wake was the final literary masterpiece. See the foreword of Hardy's A Mathematician's Apology, by CP Snow, Cambridge University Press, 19th printing, 2012, page 47
- 2. Written as: \[K = 10^4\,\times\,\left[- \frac{1}{N} + \sum_{i=1}^N\, \frac{i^2\,V\,(i,N)}{N^2}\right] \] Where N is the number of tokens, i denotes rank, and V (i;N) is the frequency of the token ranked i out of N. With this notation, V (1;N) is the number of words uniquely occurring in the text and V (2;N) is the number of words occurring twice; words with such properties are known as hapax legomena, and dislegomena. Following Tweedie and Baayen (1998), K can be considered as a measure of the rate at which words are repeated so small values indicate increased lexical richness.
- 3. Defined as: \[ RES = 206.835 – 1.015\,\frac{\#\,{\rm words}}{\#\,{\rm sentences}} – 84.6\,\frac{\#\,{\rm syllables}}{\#\,{\rm words}} \]
- 4. The texts were downloaded from project Gutenberg (Dubliners, A Portrait…, and Ulysses), and from Trent University, Canada (Finnegans Wake). I used the R libraries qdap, language R, NLP, openNLP and openNLPdata to compute the vocabulary distribution and the numbers of syllables and sentences in the texts.


